Transfer learning to new dataset (query to reference mapping)#
In this notebook, we train a DRVI model on reference data and transfer processes and embeddings to query data. DRVI uses the scArches approach internally. This covers:
Training DRVI
Query to reference mapping
Observe the integrated latent space in UMAP
Observe transferred factors
IMPORTANT: Set encode_covariates=True when initializing the model (not default). This ensures the model uses batch information in the encoder, which is essential for query to reference mapping.
Contact#
For questions and help requests, you can reach out in the scverse discourse.
If you found a bug, please use the issue tracker.
Install#
This notebook uses the tutorials extra of drvi-py (DRVI plus helper packages such as
leidenalg). Install it once in your environment with:
pip install "drvi-py[tutorials]"
On Colab, the next cell does this for you. Remove it if your environment is already set up.
import sys
import subprocess
# if branch is stable, will install via pypi, else will install from source
branch = "latest"
IN_COLAB = "google.colab" in sys.modules
if IN_COLAB and branch == "stable":
subprocess.check_call([sys.executable, "-m", "pip", "install", "drvi-py[tutorials]"])
elif IN_COLAB and branch != "stable":
subprocess.check_call([sys.executable, "-m", "pip", "install",
"git+https://github.com/theislab/drvi.git#egg=drvi-py[tutorials]"])
Imports#
import warnings
warnings.filterwarnings("ignore")
import anndata as ad
import scanpy as sc
import scvi
import drvi
from pathlib import Path
from drvi.model import DRVI
from drvi.utils.misc import hvg_batch
print("Last run with scvi-tools version:", scvi.__version__)
print("Last run with DRVI version:", drvi.__version__)
Last run with scvi-tools version: 1.4.3
Last run with DRVI version: 0.2.6
# Making plots prettier
sc.settings.set_figure_params(dpi=100, frameon=False)
sc.set_figure_params(dpi=100)
sc.set_figure_params(figsize=(3, 3))
from matplotlib import pyplot as plt
plt.rcParams["figure.dpi"] = 100
plt.rcParams["figure.figsize"] = (3, 3)
Config#
# Set this to false if you already trained your model and do not want to retrain.
overwrite = False
SEED = 1 # Set to None if you don't want to set seed
# Set input output directory to load data from and store model and embeddings there
# We use tmp_io/ directory in the same place as this notebook. Update accordingly.
io_dir = Path("./tmp_io/drvi_immune_128_q2r/")
io_dir.mkdir(parents=True, exist_ok=True)
io_dir
PosixPath('tmp_io/drvi_immune_128_q2r')
Download and load data#
We use the full immune dataset (SCIB, Luecken et al.) hosted on the scverse example data server. It contains all genes and all batches, which we need here to hold out an unseen study as the query and to run batch-aware HVG selection on the reference.
input_anndata_path = io_dir.parent / "Immune_ALL_human.h5ad"
adata = sc.read(
input_anndata_path,
backup_url="https://exampledata.scverse.org/scvi-tools/Immune_ALL_human.h5ad",
)
# Remove dataset with non-count values
adata = adata[adata.obs["batch"] != "Villani"].copy()
# We shuffle the data for better visualization. Otherwise order of points in UMAP will not be random.
sc.pp.subsample(adata, fraction=1.)
adata
AnnData object with n_obs × n_vars = 32484 × 12303
obs: 'batch', 'chemistry', 'data_type', 'dpt_pseudotime', 'final_annotation', 'mt_frac', 'n_counts', 'n_genes', 'sample_ID', 'size_factors', 'species', 'study', 'tissue'
layers: 'counts'
Pre-processing#
adata.X = adata.layers["counts"].copy()
sc.pp.normalize_total(adata)
sc.pp.log1p(adata)
adata
AnnData object with n_obs × n_vars = 32484 × 12303
obs: 'batch', 'chemistry', 'data_type', 'dpt_pseudotime', 'final_annotation', 'mt_frac', 'n_counts', 'n_genes', 'sample_ID', 'size_factors', 'species', 'study', 'tissue'
uns: 'log1p'
layers: 'counts'
adata.obs['study'].unique()
['Oetjen', '10X', 'Sun', 'Freytag']
Categories (4, object): ['10X', 'Freytag', 'Oetjen', 'Sun']
# Holding out an unseen dataset as query
adata_ref = adata[adata.obs['study'] != 'Sun'].copy()
adata_query = adata[adata.obs['study'] == 'Sun'].copy()
# Batch aware HVG selection (method is obtained from scIB metrics)
hvg_genes = hvg_batch(adata_ref, batch_key="batch", target_genes=2000, adataOut=False)
adata_ref = adata_ref[:, hvg_genes].copy()
adata_query = adata_query[:, hvg_genes].copy()
adata_ref, adata_query
This function is obtained from scIB metrics. Please don't forget to cite them if you use it.
Using 437 HVGs from full intersect set
Using 501 HVGs from n_batch-1 set
Using 604 HVGs from n_batch-2 set
Using 458 HVGs from n_batch-3 set
Using 2000 HVGs
(AnnData object with n_obs × n_vars = 23655 × 2000
obs: 'batch', 'chemistry', 'data_type', 'dpt_pseudotime', 'final_annotation', 'mt_frac', 'n_counts', 'n_genes', 'sample_ID', 'size_factors', 'species', 'study', 'tissue'
uns: 'log1p'
layers: 'counts',
AnnData object with n_obs × n_vars = 8829 × 2000
obs: 'batch', 'chemistry', 'data_type', 'dpt_pseudotime', 'final_annotation', 'mt_frac', 'n_counts', 'n_genes', 'sample_ID', 'size_factors', 'species', 'study', 'tissue'
uns: 'log1p'
layers: 'counts')
# Save pre-processed data for next notebooks
if overwrite or not (io_dir / "adata_preprocessed_ref.h5ad").exists():
adata_ref.write_h5ad(io_dir / "adata_preprocessed_ref.h5ad")
if overwrite or not (io_dir / "adata_preprocessed_query.h5ad").exists():
adata_query.write_h5ad(io_dir / "adata_preprocessed_query.h5ad")
del adata
Train DRVI#
# You can also skip this cell if model is already trained
# For more details on training params please refer to the general pipeline notebook
# Setup data
DRVI.setup_anndata(
adata_ref,
layer="counts",
batch_key="batch",
# In addition to batch_key, you can also provide additional `categorical_covariate_keys`.
# DRVI supports query to reference mapping with new categorical covariates.
is_count_data=True,
)
# Setting seed (set to None if you don't want to fix seed)
scvi.settings.seed = SEED
# construct the model
model = DRVI(
adata_ref,
n_latent=128,
# IMPORTANT: you need to allow encoder to get covariates as input to be able to do query to reference mapping
encode_covariates=True,
# For encoder and decoder dims, provide a list of integers.
)
model
INFO DRVI: The model has been initialized
DRVI Latent size: 128, splits: 128, pooling of splits: 'logsumexp', Encoder dims: (128, 128), Decoder dims: (128, 128), Gene likelihood: pnb, Training status: Not Trained
n_epochs = 400
model_path = io_dir / "drvi_model"
# train the model and save (if not already trained)
if overwrite or not model_path.exists():
model.train(
max_epochs=n_epochs,
early_stopping=False,
early_stopping_patience=20,
# No need to provide `plan_kwargs` if n_epochs >= 400.
plan_kwargs={
"n_epochs_kl_warmup": n_epochs,
},
)
# Save the model
model.save(model_path, overwrite=True)
Get reference embeddings#
# Load the model
model = DRVI.load(model_path, adata_ref)
model
INFO File tmp_io/drvi_immune_128_q2r/drvi_model/model.pt already downloaded
INFO DRVI: The model is trained with DRVI version 0.2.6.
INFO DRVI: Updaging data setup config ...
INFO DRVI: Done updating data source registry. Loading in DRVI version 0.2.6.
INFO DRVI: Loading model from DRVI version 0.2.6.
INFO DRVI: Done updating model args. Loading in 0.2.6.
INFO DRVI: The model has been initialized
DRVI Latent size: 128, splits: 128, pooling of splits: 'logsumexp', Encoder dims: (128, 128), Decoder dims: (128, 128), Gene likelihood: pnb, Training status: Trained
embed_ref = ad.AnnData(model.get_latent_representation(adata_ref), obs=adata_ref.obs)
model.set_latent_dimension_stats(embed_ref, vanished_threshold=0.5)
embed_ref.write_h5ad(io_dir / "embed_ref.h5ad")
If you are interested to observe your latent space and latent factors of the reference model, please have a look at the main tutorial.
Transfer learning#
model_path = io_dir / "drvi_model_transfer"
if overwrite or not model_path.exists():
drvi.model.DRVI.prepare_query_anndata(adata_query, model)
model_transfer = drvi.model.DRVI.load_query_data(adata_query, model)
# It is important to pass plan_kwargs={"weight_decay": 0.0} to make sure reference embeddings are untouched
model_transfer.train(
max_epochs=100,
plan_kwargs={
"weight_decay": 0.0,
}
)
model_transfer.save(model_path, overwrite=True)
model_transfer = DRVI.load(model_path, adata_query)
INFO Found 100.0% reference vars in query data.
INFO DRVI: The model is trained with DRVI version 0.2.6.
INFO DRVI: Updaging data setup config ...
INFO DRVI: Done updating data source registry. Loading in DRVI version 0.2.6.
INFO DRVI: The model is trained with DRVI version 0.2.6.
INFO DRVI: Updaging data setup config ...
INFO DRVI: Done updating data source registry. Loading in DRVI version 0.2.6.
INFO DRVI: Loading model from DRVI version 0.2.6.
INFO DRVI: Done updating model args. Loading in 0.2.6.
INFO DRVI: The model has been initialized
Resizing z_encoder.encoder.fc_layers.Layer 0.0.weight from torch.Size([128, 2005]) to torch.Size([128, 2009])
Resizing decoder.px_shared_decoder.fc_layers.Layer 0.0.weight from torch.Size([128, 133]) to torch.Size([128, 137])
Freezing key z_encoder.encoder.fc_layers.Layer 0.0.bias
Freezing key z_encoder.encoder.fc_layers.Layer 1.0.weight
Freezing key z_encoder.encoder.fc_layers.Layer 1.0.bias
Freezing key z_encoder.mean_encoder.fc_layers.Layer 0.0.weight
Freezing key z_encoder.mean_encoder.fc_layers.Layer 0.0.bias
Freezing key z_encoder.var_encoder.fc_layers.Layer 0.0.weight
Freezing key z_encoder.var_encoder.fc_layers.Layer 0.0.bias
Freezing key decoder.split_transformation_weight
Freezing key decoder.px_shared_decoder.fc_layers.Layer 0.0.bias
Freezing key decoder.px_shared_decoder.fc_layers.Layer 1.0.weight
Freezing key decoder.px_shared_decoder.fc_layers.Layer 1.0.bias
Freezing key decoder.params_nets.r
Freezing key decoder.params_nets.mean.fc_layers.Layer 0.0.weight
Freezing key decoder.params_nets.mean.fc_layers.Layer 0.0.bias
Setting hooks for z_encoder.encoder
Registering backward hook parameter with shape torch.Size([128, 2009])
Freezing normalization layer z_encoder.encoder.fc_layers.Layer 0.1
Freezing normalization layer z_encoder.encoder.fc_layers.Layer 1.1
Setting hooks for z_encoder.mean_encoder
Setting hooks for z_encoder.var_encoder
Setting hooks for decoder.px_shared_decoder
Registering backward hook parameter with shape torch.Size([128, 137])
Setting hooks for decoder.params_nets.mean
INFO File tmp_io/drvi_immune_128_q2r/drvi_model_transfer/model.pt already downloaded
INFO DRVI: The model is trained with DRVI version 0.2.6.
INFO DRVI: Updaging data setup config ...
INFO DRVI: Done updating data source registry. Loading in DRVI version 0.2.6.
INFO DRVI: Loading model from DRVI version 0.2.6.
INFO DRVI: Done updating model args. Loading in 0.2.6.
INFO DRVI: The model has been initialized
Latent space#
embed_path = io_dir / "embed.h5ad"
# Create latent space data in anndata format
if overwrite or not embed_path.exists():
embed_ref = sc.read_h5ad(io_dir / "embed_ref.h5ad") # Reference
embed_query = ad.AnnData(model_transfer.get_latent_representation(), obs=adata_query.obs) # Query
# Combining the two
embed_ref.obs['split'] = 'reference'
embed_query.obs['split'] = 'query'
embed = ad.concat([embed_ref, embed_query], join='outer')
embed.var = embed_ref.var.copy()
sc.pp.neighbors(embed, n_neighbors=10, use_rep="X", n_pcs=embed.X.shape[1])
sc.tl.umap(embed, spread=1.0, min_dist=0.5, random_state=123)
sc.pp.pca(embed)
embed.write_h5ad(embed_path)
embed
AnnData object with n_obs × n_vars = 32484 × 128
obs: 'batch', 'chemistry', 'data_type', 'dpt_pseudotime', 'final_annotation', 'mt_frac', 'n_counts', 'n_genes', 'sample_ID', 'size_factors', 'species', 'study', 'tissue', '_scvi_batch', '_scvi_labels', 'split'
var: 'original_dim_id', 'reconstruction_effect', 'order', 'max_value', 'mean', 'min', 'max', 'std', 'std_abs', 'title', 'vanished', 'vanished_positive_direction', 'vanished_negative_direction'
uns: 'neighbors', 'umap', 'pca'
obsm: 'X_umap', 'X_pca'
varm: 'PCs'
obsp: 'distances', 'connectivities'
embed = sc.read_h5ad(embed_path)
sc.pl.umap(embed, color=["batch", "split", "final_annotation"], ncols=1, frameon=False)
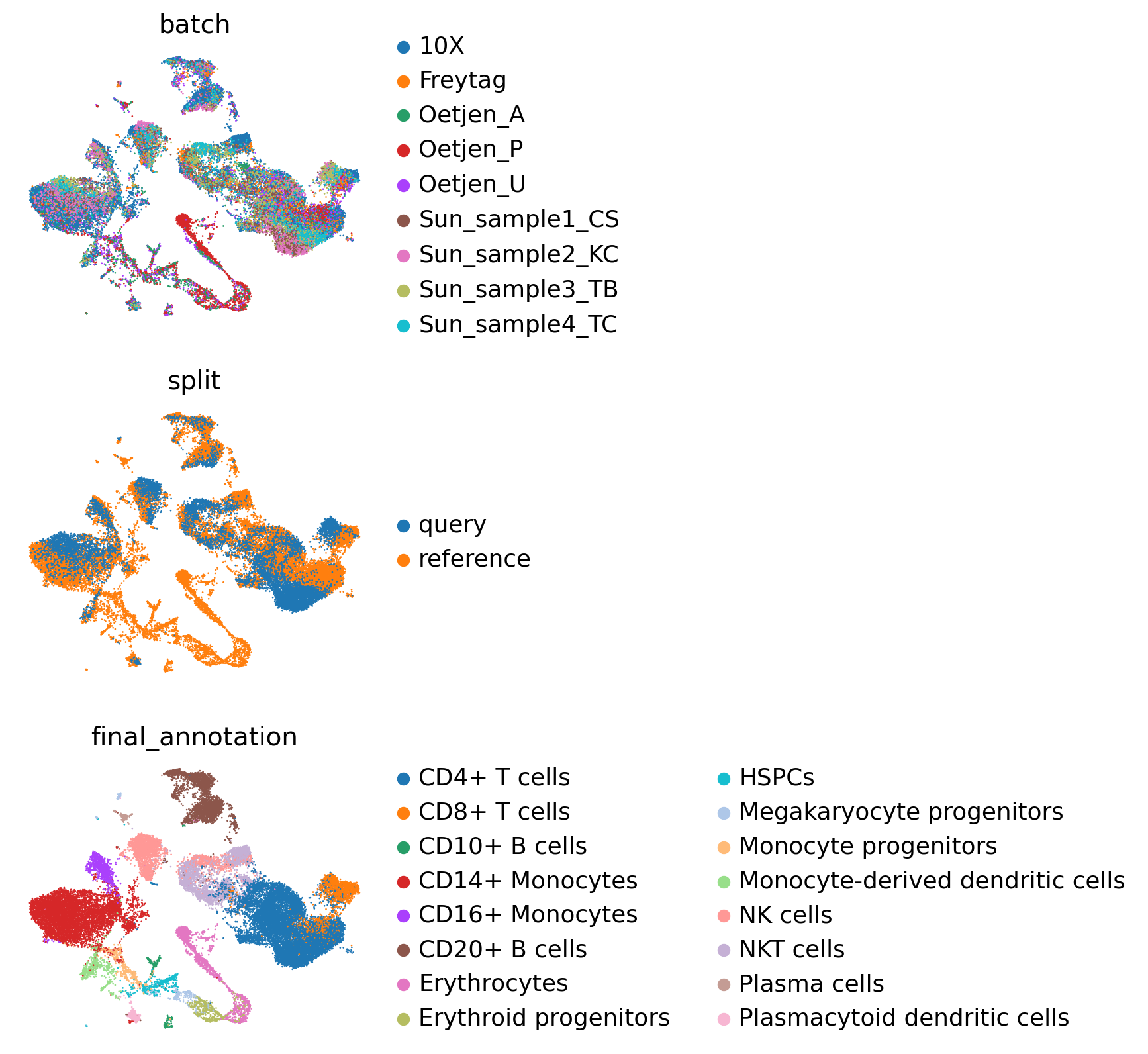
sc.pl.umap(embed, mask_obs=embed.obs['split']=='query', color=["final_annotation"], ncols=1, frameon=False)

Plot latent dimensions#
By default, vanished dimensions are not plotted. Change arguments if you would like to.
UMAP of factors for all cells#
drvi.utils.pl.plot_latent_dims_in_umap(embed)
UMAP of factors for query cells#
drvi.utils.pl.plot_latent_dims_in_umap(
embed,
mask_obs=embed.obs['split']=='query',
)
Heatmaps#
drvi.utils.pl.plot_latent_dims_in_heatmap(embed_ref, "final_annotation", title_col="title")
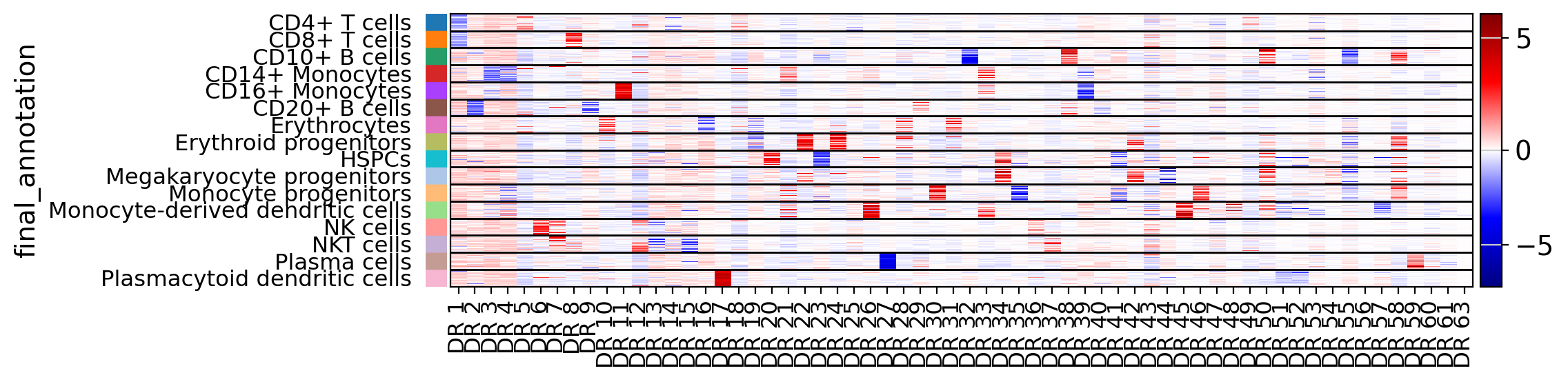
embed_query.var = embed_ref.var.copy()
drvi.utils.pl.plot_latent_dims_in_heatmap(embed_query, "final_annotation", title_col="title")

Notes#
For more details such as interpretability of latent factors please refer to other tutorials.